
Unstructured data now accounts for over 80% of enterprise data, driven by AI training datasets, IoT-generated logs, video files, and large-scale data analytics.
Poor unstructured data management leads to high storage costs, security vulnerabilities, and slow retrieval speeds.
Organizations using AWS S3, Azure Blob, or Google Cloud Storage must implement scalable, cost-efficient, and secure storage strategies to ensure long-term accessibility and compliance.
Table of Contents
1. Use Object Storage for Scalability and Cost-Efficiency

Object storage is optimized for unstructured data management, providing unlimited scalability and metadata-rich storage. Unlike block or file storage, object storage allows for distributed access across cloud regions.
Why Object Storage is Best for Unstructured Data
- Scales indefinitely without traditional volume constraints.
- Stores metadata-rich files, improving searchability and retrieval.
- Optimizes cost with tiered storage models like AWS S3 Intelligent-Tiering.
When to Use Object Storage
- AI training datasets, media files, backups, and large-scale analytics.
- Multi-region storage for geo-redundant disaster recovery.
Implementing object storage solutions can lead to a 65% reduction in storage capacity costs and a 59% decrease in total operational expenses.
SolvedMagazine
2. Optimize Storage Costs with Tiered Data Management
Not all unstructured data requires high-performance storage. Cloud providers offer tiered storage models to balance cost and access frequency.
| Cloud Provider | Frequent Access (Hot Tier) | Infrequent Access (Cold Tier) | Archive (Long-Term Storage) |
|---|---|---|---|
| AWS S3 | S3 Standard | S3 Infrequent Access | S3 Glacier |
| Google Cloud | Standard Storage | Nearline Storage | Coldline Storage |
| Azure Blob | Hot Storage | Cool Storage | Archive Storage |
An AI company storing raw image datasets for model training can use S3 Standard for active files but transition older datasets to S3 Glacier, cutting storage costs by 80%.
Google Cloud Storage
3. Automate Data Retention with Lifecycle Policies
Many organizations waste cloud storage by retaining outdated, redundant, or inactive data indefinitely. Lifecycle policies help automate storage transitions, deletions, and archiving.
Best Practices for Data Lifecycle Management
- Define retention periods for different types of data.
- Automate archival of old logs, backups, and inactive files.
- Prevent excessive redundancy that inflates cloud costs.
At least 30% of an organization’s unstructured data is redundant, obsolete, or trivial (ROT), leading to unnecessary storage expenses.
TechTarget
For better efficiency in Cloud Storage for AI Processing, see our article on Best Tips on Cloud Storage Optimization for AI Data Processing.
4. Reduce Retrieval Latency with Caching & Edge Storage
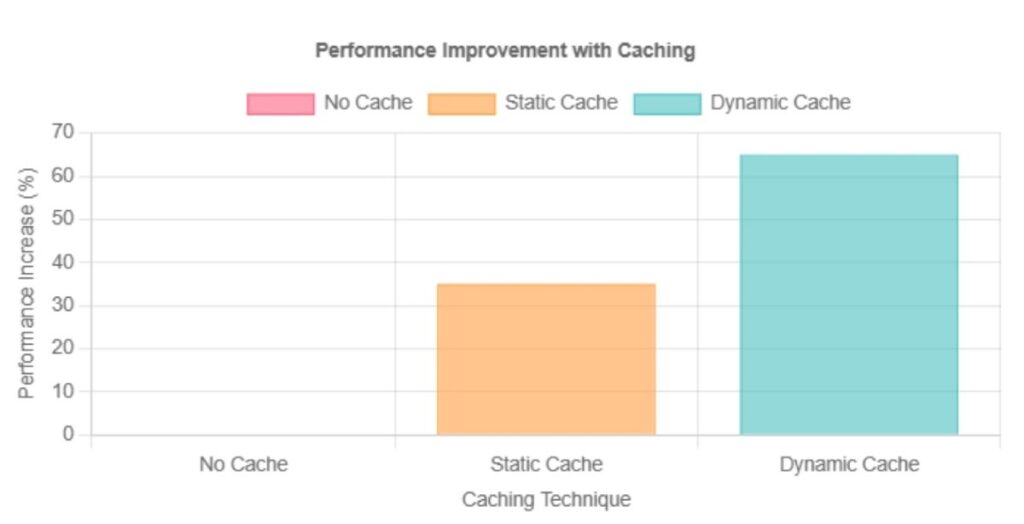
Unstructured data management, especially video files, analytics datasets, and AI workloads, requires fast retrieval speeds.
Cloud-based caching and edge storage reduce access delays.
Techniques for Optimizing Performance:
- Deploy Cloud CDN services (AWS CloudFront, Google Cloud CDN) to cache frequently accessed files near users.
- Pre-load critical data into NVMe-backed storage for AI model training.
- Implement data partitioning strategies to speed up queries and retrievals.
Studies indicate that offloading tasks to nearby edge servers can reduce latency by up to 50%, enhancing user experience.
NSF
5. Secure Unstructured Data with Encryption & Access Controls
Unstructured data is a major security risk if left unprotected. Misconfigured cloud storage permissions have led to massive data breaches.
Security Best Practices
- Enable server-side encryption (SSE) on all object storage.
- Implement role-based IAM policies to restrict access.
- Use immutable storage for compliance-heavy industries like finance and healthcare.
A financial firm storing sensitive customer documents in Google Cloud Storage enforces object-level access controls and encryption keys to prevent unauthorized access.
NIST
6. Backup & Disaster Recovery: Redundancy is Not Enough
Cloud redundancy ensures availability, but it does not protect against accidental deletions, ransomware, or data corruption. Many organizations mistakenly assume redundancy replaces the need for backups.
| Aspect | Redundancy | Backup |
|---|---|---|
| Purpose | Prevents downtime from hardware failures. | Restores historical versions of data. |
| Scope | Copies data immediately in real time. | Retains past versions for rollback. |
| Protection Against | Hardware failure, Cloud outages. | Data corruption, Ransomware, Accidental deletion. |
Backup Best Practices
- Use cross-region replication for high-availability backups.
- Enable versioning to track changes and restore previous file versions.
- Store long-term backups in cold storage tiers to reduce costs.
Conclusion: Best Practices for Unstructured Data Management
Unstructured data management requires different storage strategies than structured databases.
Organizations storing AI datasets, multimedia, analytics, and logs must:
- Use object storage for scalability and metadata management.
- Optimize costs with tiered storage and lifecycle policies.
- Reduce latency with caching and intelligent retrieval strategies.
- Secure sensitive data with encryption, IAM policies, and backups.
Ignoring best practices leads to escalating costs, security risks, and inefficient retrieval times.
Proper cloud storage planning ensures long-term efficiency, security, and cost control.
